Introduction: Juvenile Idiopathic Arthritis (JIA) is an exclusion diagnosis that encompasses all the forms of otherwise unexplained chronic arthritis occurring under the age 16.
The current classification was proposed in 1995 by the International League of Associations for Rheumatology (ILAR) and contains seven categories. However, increasing evidence suggests that some of these categories are heterogeneous. Therefore, it is necessary to revise the criteria, by identifying homogeneous entities and distinguishing those diseases present only in children from those that represent the childhood counterpart of adult diseases.
The aim of the JIA Classification protocol by PRINTO (Paediatric Rheumatology INternational Trials Organisation) is to identify a new classification through an empirical analysis, in a prospective collection of at least 1000 patients affected by arthritis at disease onset. In this paper, we present the statistical analysis conducted to identify clusters of patients affected by these diseases.
Methods: We conduct an unsupervised analysis based on machine learning algorithms on a dataset composed of 957 patients (for which now we have the complete information) and approximately 900 variables, including demographic characteristics, laboratory tests, family history and clinical information.
Patients are not filtered in order to maintain the population as uniform as possible. Some variables present missing values for more than 95% of patients and are deleted. Others are summarized by adding them up, like the ones related to the joint assessment form. Lastly, in order to have all the features on the same scale, normalization is performed by scaling between 0 and 1. Thus, our final dataset presents 957 patients and 160 variables.
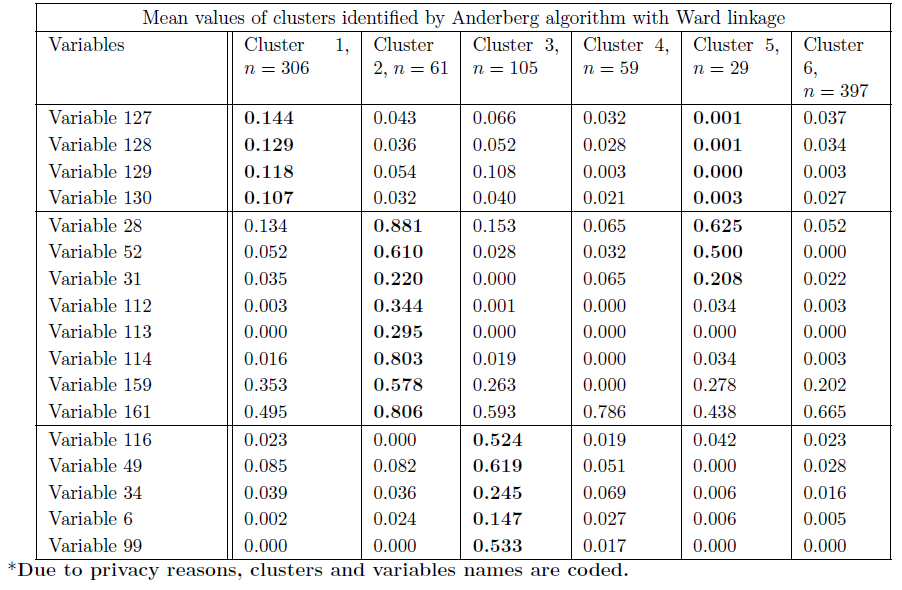
Results: At first, the Anderberg algorithm with Ward linkage is implemented, since it can deal with missing values and can be seen as a preliminary explorative analysis. The dendrogram is cut at height 6 since it represents the right compromise for sizes of the clusters. By analyzing the mean values inside each cluster, four of them can be identified as patients affected by systemic, polyarticular, enthesitis-related arthritis and undifferentiated. The other two seem homogeneous and contain patients with few arthritis-related manifestations. Given the large size of the undifferentiated cluster, another method is employed.
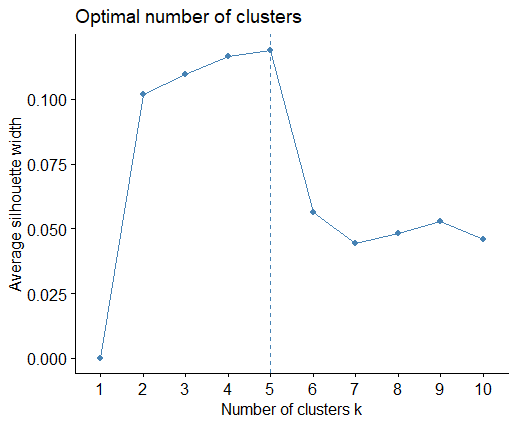
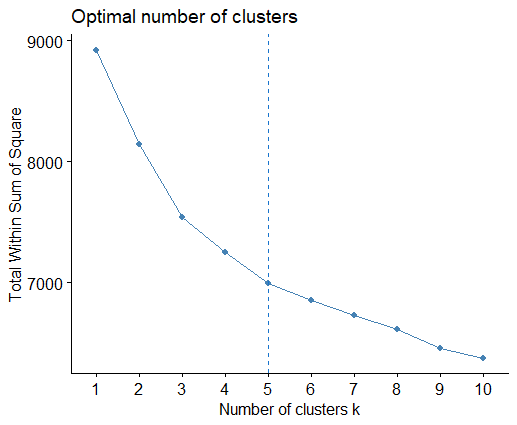
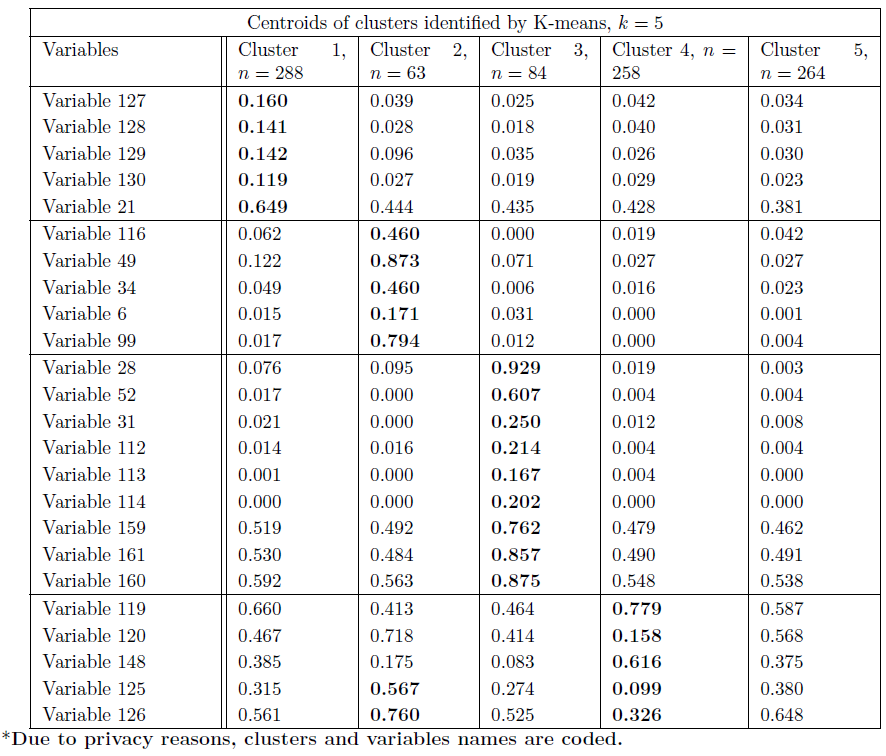
After a missing value investigation, the K-means algorithm is implemented. The analysis of Silhouette and Wss plots suggests the choice of k=5. Also K-means identifies the four groups mentioned before, but additionally, it detects a cluster of patients with ANA positive tests and a predominant young female presence. Repeating the analysis with different seeds, the clusters remain stable.
Conclusions: Both methods are able to identify homogeneous clusters (low within variances). However, the choice of k=5 is less arbitrary than the cut of the dendrogram and, in K-means, the size of the undifferentiated group is smaller. Lastly, one group does not have a definite characterization in Anderberg. Other analyses, by using the complete dataset (once the data collection is over, we will have the information of approximately 1500 patients) and by applying DBSCAN, will be performed in the next three months.